If I could give one advice to fellow developer(s) without knowing anything about their background or skill level it would be to turn on Break When Thrown for all CLR exceptions. I have witnessed developers less experienced and more experienced lose too much time trying to pinpoint the location where exception gets thrown.
How to enable the setting
Find it under Debug -> Windows -> Exception Settings
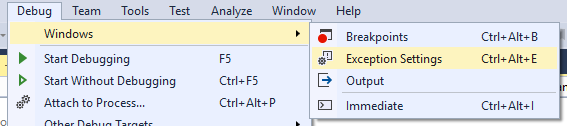
and ensure that checkbox next to Common Language Runtime Exceptions is checked.
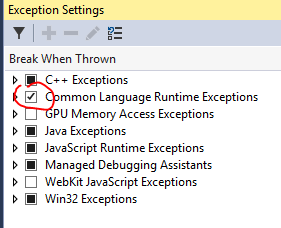
Now, whenever an exception is thrown, Visual Studio will break and show the line where exception has happened.
Be aware that this setting, together with Just My Code unchecked, might break on a few exceptions which are caught and handled in .NET Framework or referenced libraries.
Impact of the setting
To illustrate difference in debugging experience, let’s look at a sample console application, first without checkbox checked and then with checkbox checked.
using System;
namespace Calculator
{
class Program
{
static void Main(string[] args)
{
var result = ComplicatedCalculation();
Console.ReadLine();
}
private static int ComplicatedCalculation()
{
try
{
return ComplicatedSubCalculation();
}
catch
{
// log
throw;
}
}
private static int ComplicatedSubCalculation()
{
try
{
return SimpleCalculation(7);
}
catch
{
// log
throw;
}
}
private static int SimpleCalculation(int arg)
{
throw new NotImplementedException();
}
}
}When running this code with debugging (F5) Visual Studio breaks on outermost throw statement.
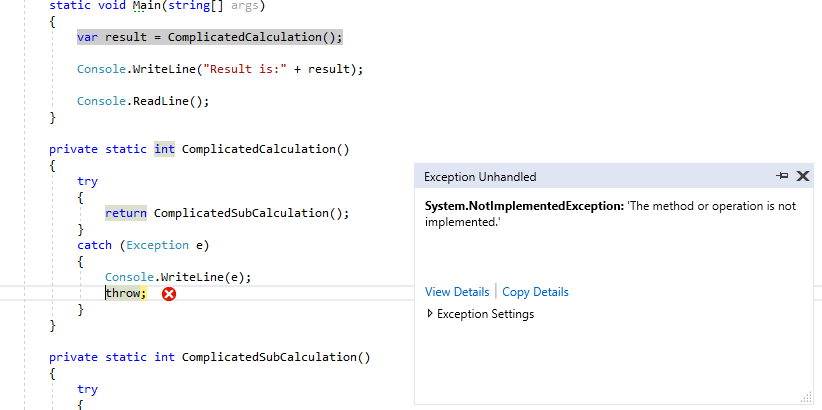
Not very obvious that it is SimpleCalculation that is in fact not implemented. Also, when looking at the exception here, there is no data available about original call stack which is very useful since it includes values of method parameters.
Often, top level code is wrapped in try .. catch .. so that the application can survive unplanned exceptions.
static void Main(string[] args)
{
try
{
var result = ComplicatedCalculation();
Console.WriteLine("Result is:" + result);
}
catch (Exception e)
{
Console.WriteLine(e);
}
Console.ReadLine();
}After running the application now, we get the following console output:

So, exception has occurred and all the data is here - file name and line number where the exception is thrown. But in real life, this can be buried in log files and we might even be unaware that the exception has happened. Then it looks more like this:
![]()
Now, let’s check the checkbox and run the application:
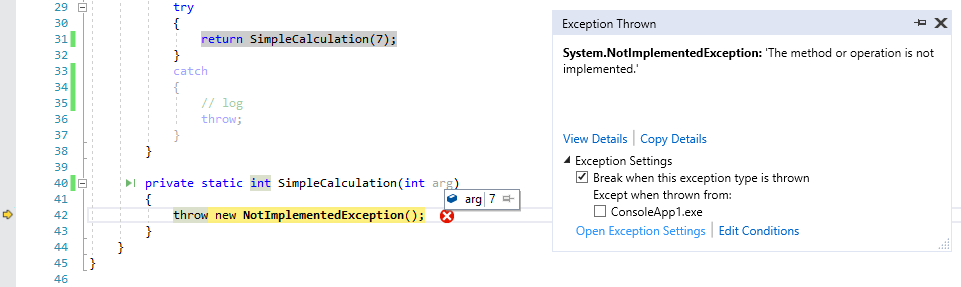
Debugger helpfully stops on first exception and argument values are available.
Side note
Sometimes, this little gem automatically unchecks itself, so for quicker access shortcut Ctrl+Alt+E is rather useful.